Thursday, November 29, 2007
Sunday, November 11, 2007

Monday, November 5, 2007
Perceptual coding: The miracle of acoustic masking
All of the MPEG perceptual codecs rely upon the celebrated acoustic masking principle – an amazing property of the human ear/brain aural perception system. When audio is present at a particular frequency, you cannot hear audio at nearby frequencies that are sufficiently low in volume. The inaudible components are masked owing to properties of the human ear that occur at a very low ‘hardware’ level – researchers say the information is dropped straightaway within the ear and is not passed to the brain. This appears to be a kind of ‘natural rate reduction’ that helps to keep the brain from being overloaded with unnecessary information. There is a similar effect working in the time domain, with signals coming soon after the removal of another being also inaudible.

 As a result, it is not necessary to use precious bits to encode these masked frequencies. In perceptual coders, a filter bank divides the audio into multiple bands. When audio in a particular band falls below the masking threshold, few or no bits are devoted to encoding that signal, resulting in a conservation of bits that can then be used where they are needed.
As a result, it is not necessary to use precious bits to encode these masked frequencies. In perceptual coders, a filter bank divides the audio into multiple bands. When audio in a particular band falls below the masking threshold, few or no bits are devoted to encoding that signal, resulting in a conservation of bits that can then be used where they are needed.
 While various codecs use different techniques in the details, the principle is the same for all, and the implementation follows a common plan. There are four major subsections, which work together to generate the coded bitstream:
While various codecs use different techniques in the details, the principle is the same for all, and the implementation follows a common plan. There are four major subsections, which work together to generate the coded bitstream:
As a result, it is not necessary to use precious bits to encode these masked frequencies. In perceptual coders, a filter bank divides the audio into multiple bands. When audio in a particular band falls below the masking threshold, few or no bits are devoted to encoding that signal, resulting in a conservation of bits that can then be used where they are needed.While various codecs use different techniques in the details, the principle is the same for all, and the implementation follows a common plan. There are four major subsections, which work together to generate the coded bitstream:- The analysis filter bank divides the audio into spectral components. At minimum, sufficient frequency resolution must be used in order to exceed the width of the ear's critical bands, which have widths of 100 Hz below 500 Hz and roughly 20% of the center frequency at higher frequencies. Finer resolution can help a coder make better decisions.
- The estimation of masked threshold section is where the human ear/brain system is modeled. This determines the masking curve, under which noise must fall.
- The audio is reduced to a lower bitrate in the quantization and coding section. On the one hand, the quantization must be sufficiently course in order not to exceed the target bitrate. On the other hand, the error must be shaped to be under the limits set by the masking curve.
- The quantized values are joined in the bitstream multiplex, along with any side information.
Source: telos-systems
Tuesday, October 30, 2007
Overview: YUV formats
The YUV model defines a color space in terms of one luma and two chrominance components.
There 4 main YUV formats:
- YUV444 : Each point is represented by a (Y,U,V) value. The size of this format is the same with the RGB format size.
- YUV422 : Each block 2x1 is represented by one (U,V) value and two different Y values for each point in that block. The size of this format is smaller than the RGB format size.
- YUV420 : Each block 2x2 is represented by one (U,V) value and four different Y values for each point in that block. The size of this format is smaller than the RGB format and the YUV422 format size.
- YUV411 : Each block 4x1 is represented by one (U,V) value and four different Y values for each point in that block. The size of this format is the same with the YUV420 format size.
We use the YUV formats because the human eye is more sensitive to the luminance than the chrominance. So that we can reduce the chrominance coefficients to reduce the size of the picture or video frame (YUV422, YUV420, YUV411).
Note: in block AxB, A is the horizontal dimension and B is the vertical dimension.
Reference:
- Wikipedia
- http://www.fourcc.org/yuv.php
There 4 main YUV formats:
- YUV444 : Each point is represented by a (Y,U,V) value. The size of this format is the same with the RGB format size.
- YUV422 : Each block 2x1 is represented by one (U,V) value and two different Y values for each point in that block. The size of this format is smaller than the RGB format size.
- YUV420 : Each block 2x2 is represented by one (U,V) value and four different Y values for each point in that block. The size of this format is smaller than the RGB format and the YUV422 format size.
- YUV411 : Each block 4x1 is represented by one (U,V) value and four different Y values for each point in that block. The size of this format is the same with the YUV420 format size.
We use the YUV formats because the human eye is more sensitive to the luminance than the chrominance. So that we can reduce the chrominance coefficients to reduce the size of the picture or video frame (YUV422, YUV420, YUV411).
Note: in block AxB, A is the horizontal dimension and B is the vertical dimension.
Reference:
- Wikipedia
- http://www.fourcc.org/yuv.php
Wednesday, October 24, 2007
Effective Teamworks
Books: Software Configuration Management Patterns: Effective Teamwork, Practical Integration
- Investigating patterns of SCM pattern language to improve the team 's productivity.
- The main section of this book is the way to keep the development line active and progressive.
- This blogger has just read the first 5 patterns of this book and used WinCVS to practice the Mainline pattern.
- Investigating patterns of SCM pattern language to improve the team 's productivity.
- The main section of this book is the way to keep the development line active and progressive.
- This blogger has just read the first 5 patterns of this book and used WinCVS to practice the Mainline pattern.
Monday, October 22, 2007
Video Compression: H261 & MPEG1 Standard
Source: https://www.cs.sfu.ca/
MPEG
Newer MPEG Standards







Further Exploration
The MPEG Home Page, A good MPEG FAQ, MPEG Resources on the Web.
4.3. Video Compression
H. 261MPEG
Newer MPEG Standards
Reference: Chapter 6 of Steinmetz and Nahrstedt
- Uncompressed video data are huge. In HDTV, the bit-rate could exceed 1 Gbps. --> big problems for storage and network communications.
- We will discuss both Spatial and Temporal Redundancy Removal -- Intra-frame and Inter-frame coding.
4.3.1. H. 261
- Developed by CCITT (Consultative Committee for International Telephone and Telegraph) in 1988-1990
- Designed for videoconferencing, video-telephone applications over ISDN telephone lines.
Bit-rate is p x 64 Kb/sec, where p ranges from 1 to 30.
1. Overview of H. 261
- Frame Sequence

- Frame types are CCIR 601 CIF (352 x 288) and QCIF (176 x 144) images with 4:2:0 subsampling.
- Two frame types: Intra-frames (I-frames) and Inter-frames (P-frames):
I-frame provides an accessing point, it uses basically JPEG.
P-frames use "pseudo-differences" from previous frame ("predicted"), so frames depend on each other.

2. Intra-frame Coding

- Macroblocks are 16 x 16 pixel areas on Y plane of original image.
A macroblock usually consists of 4 Y blocks, 1 Cr block, and 1 Cb block.
- Quantization is by constant value for all DCT coefficients (i.e., no quantization table as in JPEG).
3. Inter-frame (P-frame) Coding
- An Coding Example (P-frame)

- Previous image is called reference image, the image to encode is called target image.
- Points to emphasize:
- The difference image (not the target image itself) is encoded.
- Need to use the decoded image as reference image, not the original.
- We're using "Mean Absolute Error" (MAE) to decide best block.
Can also use "Mean Squared Error" (MSE) = sum(E*E)/N
- The difference image (not the target image itself) is encoded.

4. H. 261 Encoder

- "Control" -- controlling the bit-rate. If the transmission buffer is too full, then bit-rate will be reduced by changing the quantization factors.
- "memory" -- used to store the reconstructed image (blocks) for the purpose of motion vector search for the next P-frame.
5. Methods for Motion Vector Searches

- C(x + k, y + l) -- pixels in the macro block with upper left corner (x, y) in the Target frame.
R(x + i + k, y + j + l) -- pixels in the macro block with upper left corner (x + i, y + j) in the Reference frame.
Cost function is:

- Goal is to find a vector (u, v) such that MAE(u, v) is minimum.

5.1 Full Search Method
- Sequentially search the whole [-p, p] region --> very slow
5.2 Two-Dimensional Logarithmic Search
- Similar to binary search. MAE function is initially computed within a window of [-p/2, p/2] at nine locations as shown in the figure.
- Find one of the nine locations that yields the minimum MAE
- Form a new searching region with half of the previous size and centered at the location found in step 1.
Repeat until the size of the search region is one pixel wide:

5.3 Hierarchical Motion Estimation

- Form several low resolution version of the target and reference pictures
- Find the best match motion vector in the lowerest resolution version.
- Modify the motion vector level by level when going up
6. Some Important Issues
- Avoiding propagation of errors
- Send an I-frame every once in a while
- Make sure you use decoded frame for comparison
- Send an I-frame every once in a while
- Bit-rate control
- Simple feedback loop based on "buffer fullness"
If buffer is too full, increase the quantization scale factor to reduce the data.
- Simple feedback loop based on "buffer fullness"
7. Details
7.1 How the Macroblock is Coded ?

- Many macroblocks will be exact matches (or close enough). So send address of each block in image --> Addr
- Sometimes no good match can be found, so send INTRA block --> Type
- Will want to vary the quantization to fine tune compression, so send quantization value --> Quant
- Motion vector --> vector
- Some blocks in macroblock will match well, others match poorly. So send bitmask indicating which blocks are present (Coded Block Pattern, or CBP).
- Send the blocks (4 Y, 1 Cr, 1 Cb) as in JPEG.
7.2. H. 261 Bitstream Structure

- Need to delineate boundaries between pictures, so send Picture Start Code --> PSC
- Need timestamp for picture (used later for audio synchronization), so send Temporal Reference --> TR
- Is this a P-frame or an I-frame? Send Picture Type --> PType
- Picture is divided into regions of 11 x 3 macroblocks called Groups of Blocks --> GOB
- Might want to skip whole groups, so send Group Number (Grp #)
- Might want to use one quantization value for whole group, so send Group Quantization Value --> GQuant
- Overall, bitstream is designed so we can skip data whenever possible while still unambiguous.
1. What is MPEG ?
- "Moving Picture Coding Experts Group", established in 1988 to create standard for delivery of video and audio.
- MPEG-1 Target: VHS quality on a CD-ROM (352 x 288 + CD audio @ 1.5 Mbits/sec)
- Standard had three parts: Video, Audio, and System (control interleaving of streams)
2. MPEG Video
- Problem: some macroblocks need information not in the previous reference frame.
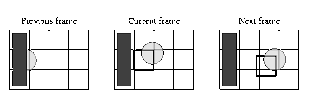 Example: The darkened macroblock in Current frame does not have a good match from the Previous frame, but it will find a good match in the Next frame.
Example: The darkened macroblock in Current frame does not have a good match from the Previous frame, but it will find a good match in the Next frame. - MPEG solution: add third frame type: bidirectional frame, or B-frame
In B-frames, search for matching macroblocks in both past and future frames.
- Typical pattern is IBBPBBPBB IBBPBBPBB IBBPBBPBB
Actual pattern is up to encoder, and need not be regular.



3. Differences from H. 261
- Larger gaps between I and P frames, so need to expand motion vector search range.
- To get better encoding, allow motion vectors to be specified to fraction of a pixel (1/2 pixel).
- Bitstream syntax must allow random access, forward/backward play, etc.
- Added notion of slice for synchronization after loss/corrupt data. Example: picture with 7 slices:

- B frame macroblocks can specify two motion vectors (one to past and one to future), indicating result is to be averaged.

- Compression performance of MPEG 1
------------------------------
Type Size Compression
------------------------------
I 18 KB 7:1
P 6 KB 20:1
B 2.5 KB 50:1
Avg 4.8 KB 27:1
------------------------------


4. MPEG Video Bitstream
- Click here for details
- Public domain tool
mpeg_statandmpeg_bitswill analyze a bitstream.
5. Decoding MPEG Video in Software
- Software Decoder goals: portable, multiple display types
- Breakdown of time
-------------------------
Function % Time
Parsing Bitstream 17.4%
IDCT 14.2%
Reconstruction 31.5%
Dithering 24.5%
Misc. Arith. 9.9%
Other 2.7%
-------------------------
4.3.3. Newer MPEG Standards
1. MPEG-2
- Unlike MPEG-1 which is basically a standard for storing and playing video on a single computer at low bit-rates, MPEG-2 is a standard for digital TV. It meets the requirements for HDTV and DVD (Digital Video/Versatile Disc).
---------------------------------------------------------------------------
Level size Pixels/sec bit-rate Application
(Mbits)
---------------------------------------------------------------------------
Low 352 x 288 x 30 3 M 4 consumer tape equiv.
Main 720 x 576 x 30 12 M 15 studio TV
High 1440 1440 x 1152 x 60 96 M 60 consumer HDTV
High 1920 x 1152 x 60 128 M 80 film production
---------------------------------------------------------------------------
- Other Differences from MPEG-1:
- Support both field prediction and frame prediction.
- Besides 4:2:0, also allow 4:2:2 and 4:4:4 chroma subsampling
- Scalable Coding Extensions: (so the same set of signals works for both HDTV and standard TV)
- SNR (quality) Scalability -- similar to JPEG DCT-based Progressive mode, adjusting the quantization steps of the DCT coefficients.
- Spatial Scalability -- similar to hierarchical JPEG, multiple spatial resolutions.
- Temporal Scalability -- different frame rates.
- SNR (quality) Scalability -- similar to JPEG DCT-based Progressive mode, adjusting the quantization steps of the DCT coefficients.
- Frame sizes could be as large as 16383 x 16383
- Non-linear macroblock quantization factor
- Many minor fixes (see MPEG FAQ for more details)
- Support both field prediction and frame prediction.
- MPEG-3: Originally planned for HDTV, got folded into MPEG-2
2. MPEG-4
- Version 1 approved Oct. 1998, Version 2 to be approved Dec. 1999.
- Originally targeted at very low bit-rate communication (4.8 to 64 Kb/sec), it now aims at the following ranges of bit-rates:
- video -- 5 Kb to 5 Mb per second
- audio -- 2 Kb to 64 Kb per second
- It emphasizes the concept of Visual Objects --> Video Object Plane (VOP)
- objects can be of arbitrary shape, VOPs can be non-overlapped or overlapped
- supports content-based scalability
- supports object-based interactivity
- individual audio channels can be associated with objects
- Good for video composition, segmentation, and compression; networked VRML, audiovisual communication systems (e.g., text-to-speech interface, facial animation), etc.
- Standards being developed for shape coding, motion coding, texture coding, etc.
3. MPEG-7 (Multimedia Content Description Interface)
- International Standard due by July 2001.
- MPEG-7 is a content representation standard for multimedia information search, filtering, management and processing.
- Descriptors for multimedia objects and Description Schemes for the descriptors and their relationships.
- A Description Definition Language (DLL) for specifying Description Schemes.
- For visual contents, the lower level descriptions will be color, texture, shape, size, etc., the higher level could include a semantic description such as "this is a scene with cars on the highway".
- Descriptors for multimedia objects and Description Schemes for the descriptors and their relationships.
Further Exploration 
The MPEG Home Page, A good MPEG FAQ, MPEG Resources on the Web.
Subscribe to:
Posts (Atom)